Simply as there are broadly understood empirical legal guidelines of nature — for instance, what goes up should come down, or each motion has an equal and reverse response — the sphere of AI was lengthy outlined by a single thought: that extra compute, extra coaching information and extra parameters makes a greater AI mannequin.
Nonetheless, AI has since grown to wish three distinct legal guidelines that describe how making use of compute sources in numerous methods impacts mannequin efficiency. Collectively, these AI scaling legal guidelines — pretraining scaling, post-training scaling and test-time scaling, additionally referred to as lengthy considering — mirror how the sphere has developed with methods to make use of extra compute in all kinds of more and more advanced AI use instances.
The latest rise of test-time scaling — making use of extra compute at inference time to enhance accuracy — has enabled AI reasoning fashions, a brand new class of huge language fashions (LLMs) that carry out a number of inference passes to work via advanced issues, whereas describing the steps required to unravel a job. Take a look at-time scaling requires intensive quantities of computational sources to help AI reasoning, which is able to drive additional demand for accelerated computing.
What Is Pretraining Scaling?
Pretraining scaling is the unique regulation of AI growth. It demonstrated that by rising coaching dataset measurement, mannequin parameter depend and computational sources, builders may anticipate predictable enhancements in mannequin intelligence and accuracy.
Every of those three components — information, mannequin measurement, compute — is interrelated. Per the pretraining scaling regulation, outlined on this analysis paper, when bigger fashions are fed with extra information, the general efficiency of the fashions improves. To make this possible, builders should scale up their compute — creating the necessity for highly effective accelerated computing sources to run these bigger coaching workloads.
This precept of pretraining scaling led to massive fashions that achieved groundbreaking capabilities. It additionally spurred main improvements in mannequin structure, together with the rise of billion- and trillion-parameter transformer fashions, combination of consultants fashions and new distributed coaching methods — all demanding vital compute.
And the relevance of the pretraining scaling regulation continues — as people proceed to provide rising quantities of multimodal information, this trove of textual content, photos, audio, video and sensor data might be used to coach highly effective future AI fashions.
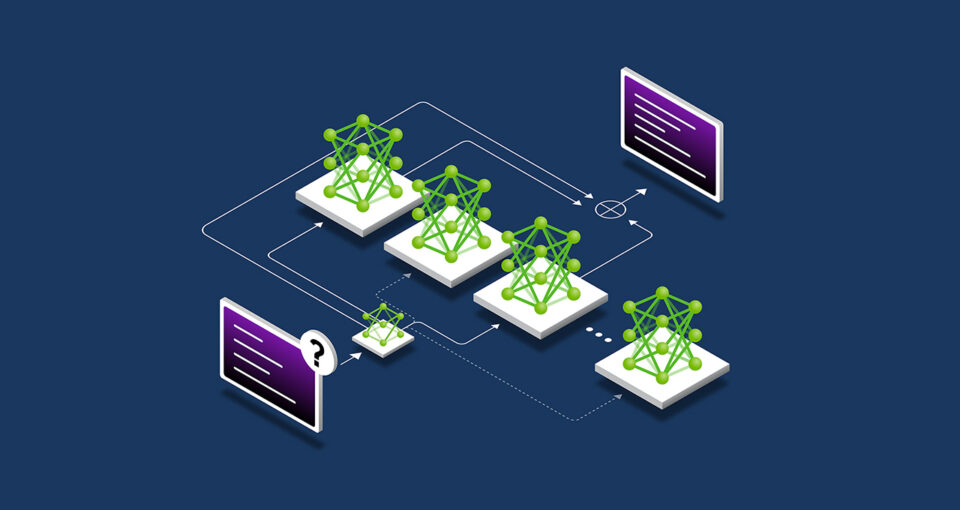
What Is Submit-Coaching Scaling?
Pretraining a big basis mannequin isn’t for everybody — it takes vital funding, expert consultants and datasets. However as soon as a company pretrains and releases a mannequin, they decrease the barrier to AI adoption by enabling others to make use of their pretrained mannequin as a basis to adapt for their very own functions.
This post-training course of drives extra cumulative demand for accelerated computing throughout enterprises and the broader developer group. Widespread open-source fashions can have a whole bunch or 1000’s of by-product fashions, skilled throughout quite a few domains.
Growing this ecosystem of by-product fashions for quite a lot of use instances may take round 30x extra compute than pretraining the unique basis mannequin.
Growing this ecosystem of by-product fashions for quite a lot of use instances may take round 30x extra compute than pretraining the unique basis mannequin.
Submit-training methods can additional enhance a mannequin’s specificity and relevance for a company’s desired use case. Whereas pretraining is like sending an AI mannequin to high school to study foundational abilities, post-training enhances the mannequin with abilities relevant to its meant job. An LLM, for instance, might be post-trained to deal with a job like sentiment evaluation or translation — or perceive the jargon of a particular area, like healthcare or regulation.
The post-training scaling regulation posits {that a} pretrained mannequin’s efficiency can additional enhance — in computational effectivity, accuracy or area specificity — utilizing methods together with fine-tuning, pruning, quantization, distillation, reinforcement studying and artificial information augmentation.
- High quality-tuning makes use of extra coaching information to tailor an AI mannequin for particular domains and functions. This may be achieved utilizing a company’s inner datasets, or with pairs of pattern mannequin enter and outputs.
- Distillation requires a pair of AI fashions: a big, advanced instructor mannequin and a light-weight scholar mannequin. In the most typical distillation method, referred to as offline distillation, the coed mannequin learns to imitate the outputs of a pretrained instructor mannequin.
- Reinforcement studying, or RL, is a machine studying method that makes use of a reward mannequin to coach an agent to make selections that align with a particular use case. The agent goals to make selections that maximize cumulative rewards over time because it interacts with an surroundings — for instance, a chatbot LLM that’s positively bolstered by “thumbs up” reactions from customers. This method is called reinforcement studying from human suggestions (RLHF). One other, newer method, reinforcement studying from AI suggestions (RLAIF), as an alternative makes use of suggestions from AI fashions to information the training course of, streamlining post-training efforts.
- Finest-of-n sampling generates a number of outputs from a language mannequin and selects the one with the best reward rating primarily based on a reward mannequin. It’s typically used to enhance an AI’s outputs with out modifying mannequin parameters, providing a substitute for fine-tuning with reinforcement studying.
- Search strategies discover a variety of potential determination paths earlier than choosing a closing output. This post-training method can iteratively enhance the mannequin’s responses.
To help post-training, builders can use artificial information to reinforce or complement their fine-tuning dataset. Supplementing real-world datasets with AI-generated information may also help fashions enhance their skill to deal with edge instances which might be underrepresented or lacking within the authentic coaching information.

What Is Take a look at-Time Scaling?
LLMs generate fast responses to enter prompts. Whereas this course of is properly suited to getting the correct solutions to easy questions, it might not work as properly when a person poses advanced queries. Answering advanced questions — an important functionality for agentic AI workloads — requires the LLM to cause via the query earlier than developing with a solution.
It’s just like the best way most people assume — when requested so as to add two plus two, they supply an prompt reply, while not having to speak via the basics of addition or integers. But when requested on the spot to develop a marketing strategy that might develop an organization’s earnings by 10%, an individual will doubtless cause via numerous choices and supply a multistep reply.
Take a look at-time scaling, often known as lengthy considering, takes place throughout inference. As an alternative of conventional AI fashions that quickly generate a one-shot reply to a person immediate, fashions utilizing this method allocate further computational effort throughout inference, permitting them to cause via a number of potential responses earlier than arriving at the perfect reply.
On duties like producing advanced, personalized code for builders, this AI reasoning course of can take a number of minutes, and even hours — and might simply require over 100x compute for difficult queries in comparison with a single inference cross on a standard LLM, which might be extremely unlikely to provide an accurate reply in response to a fancy downside on the primary strive.
This AI reasoning course of can take a number of minutes, and even hours — and might simply require over 100x compute for difficult queries in comparison with a single inference cross on a standard LLM.
This test-time compute functionality allows AI fashions to discover totally different options to an issue and break down advanced requests into a number of steps — in lots of instances, exhibiting their work to the person as they cause. Research have discovered that test-time scaling leads to higher-quality responses when AI fashions are given open-ended prompts that require a number of reasoning and planning steps.
The test-time compute methodology has many approaches, together with:
- Chain-of-thought prompting: Breaking down advanced issues right into a sequence of easier steps.
- Sampling with majority voting: Producing a number of responses to the identical immediate, then choosing probably the most continuously recurring reply as the ultimate output.
- Search: Exploring and evaluating a number of paths current in a tree-like construction of responses.
Submit-training strategies like best-of-n sampling will also be used for lengthy considering throughout inference to optimize responses in alignment with human preferences or different aims.

How Take a look at-Time Scaling Allows AI Reasoning
The rise of test-time compute unlocks the power for AI to supply well-reasoned, useful and extra correct responses to advanced, open-ended person queries. These capabilities might be essential for the detailed, multistep reasoning duties anticipated of autonomous agentic AI and bodily AI functions. Throughout industries, they may enhance effectivity and productiveness by offering customers with extremely succesful assistants to speed up their work.
In healthcare, fashions may use test-time scaling to research huge quantities of information and infer how a illness will progress, in addition to predict potential issues that might stem from new therapies primarily based on the chemical construction of a drug molecule. Or, it may comb via a database of scientific trials to recommend choices that match a person’s illness profile, sharing its reasoning course of concerning the professionals and cons of various research.
In retail and provide chain logistics, lengthy considering may also help with the advanced decision-making required to handle near-term operational challenges and long-term strategic objectives. Reasoning methods may also help companies scale back threat and handle scalability challenges by predicting and evaluating a number of situations concurrently — which may allow extra correct demand forecasting, streamlined provide chain journey routes, and sourcing selections that align with a company’s sustainability initiatives.
And for international enterprises, this method might be utilized to draft detailed enterprise plans, generate advanced code to debug software program, or optimize journey routes for supply vehicles, warehouse robots and robotaxis.
AI reasoning fashions are quickly evolving. OpenAI o1-mini and o3-mini, DeepSeek R1, and Google DeepMind’s Gemini 2.0 Flash Considering had been all launched in the previous couple of weeks, and extra new fashions are anticipated to comply with quickly.
Fashions like these require significantly extra compute to cause throughout inference and generate appropriate solutions to advanced questions — which implies that enterprises have to scale their accelerated computing sources to ship the following era of AI reasoning instruments that may help advanced problem-solving, coding and multistep planning.
Find out about the advantages of NVIDIA AI for accelerated inference.